Current Projects

3D Targets for Evaluating Fingerprint Readers
3D Targets for Evaluating Fingerprint Readers
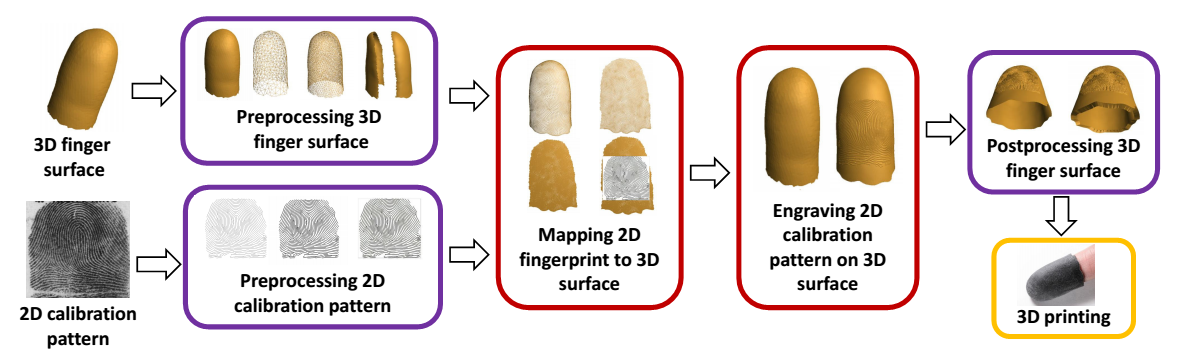
Calibration of imaging systems typically involves the use of specially designed objects with known properties, called calibration targets. Standard calibration targets are, in general, used for calibrating the imaging pathway of fingerprint readers. However, there is no standard method for evaluating fingerprint readers in the operational setting where variations in finger placement by the user are encountered. The goal of this research is to design 3D targets for repeatable operational evaluation of fingerprint readers. 2D calibration patterns with known characteristics (e.g. sinusoidal gratings of pre-specified orientation and frequency, synthetic fingerprints with known singular points and minutiae) are projected onto a generic 3D finger surface to create electronic 3D targets (see Fig. 1). A state-of-the-art 3D printer (Stratasys Objet350 Connex) is used to fabricate the 3D targets with material similar in hardness and elasticity to the human finger skin. Our experimental results show that the (i) fabricated 3D targets can be imaged using three different (500/1000 ppi) commercial optical fingerprint readers, (ii) salient features in the 2D calibration patterns are preserved during the synthesis and fabrication of 3D targets, and (iii) intra-class variability between multiple impressions of the 3D targets captured using the optical fingerprint readers does not degrade the recognition accuracy. We also conduct experiments to demonstrate that the fabricated 3D targets can be used for operational evaluation of optical fingerprint readers (see Fig. 2).
Relevant Publication(s)
1. S. S. Arora, K. Cao, A. K. Jain and N. G. Paulter Jr., "3D Targets for Evaluating Fingerprint Readers", MSU Technical Report, MSU-CSE-15-3, February 23, 2015. [pdf]
2. S. S. Arora, K. Cao, A. K. Jain and N. G. Paulter Jr., "3D Fingerprint Phantoms", 22nd International Conference on Pattern Recognition (ICPR), Stockolm, Sweden, August 24-28, 2014. [pdf][video]
3. S. S. Arora, K. Cao, A. K. Jain and N. G. Paulter Jr., "3D Fingerprint Phantoms", MSU Technical Report, MSU-CSE-13-12, December 24, 2013. [pdf][video]

A Longitudinal Study of Automatic Face Recognition
A Longitudinal Study of Automatic Face Recognition
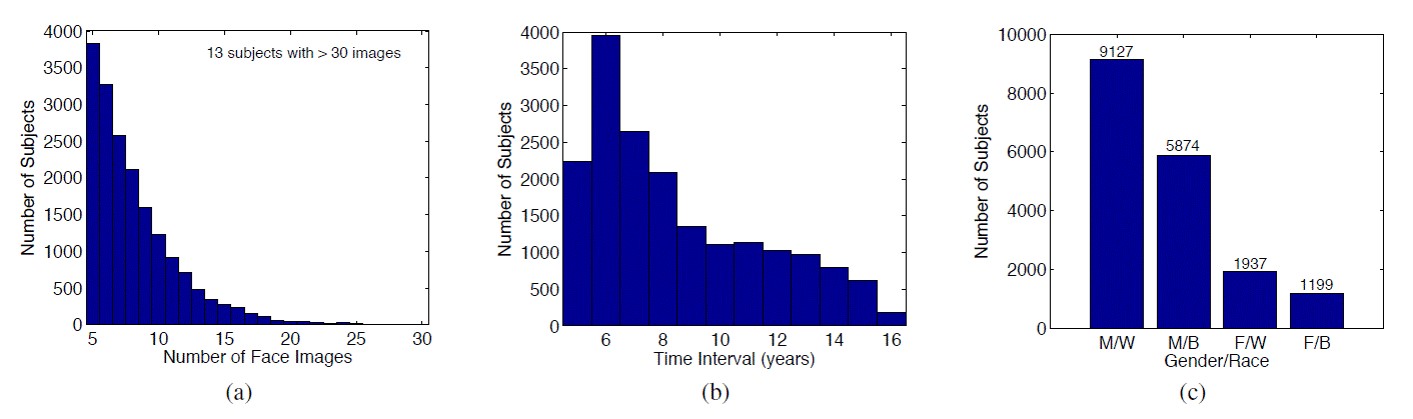
Changes in human facial characteristics over time are inevitable. Hence, it is not surprising that face matching accuracy decreases with increasing elapsed time between two face images of the same person. With the deployment of automatic face recognition systems for de-duplication and law enforcement applications, it is crucial that we gain a better understanding of how facial aging due to time lapse affects recognition performance. Some people "age well" while the facial appearance of others changes drastically over time; this disparity mandates a subject-specific aging analysis. In this ongoing project, we use multilevel statistical models on a longitudinal database of 147,784 face images of 18,007 subjects (see Figs. 1 and 2) to quantify how time lapse affects match scores and recognition accuracy. A similar approach was used by Yoon and Jain [1] for fingerprint analysis and by Grother et al. [2] for iris analysis. Using two state-of-the-art COTS face matchers, we report (i) population-mean temporal trends in genuine scores and (ii) inter-subject variations, (iii) effects of other covariates (gender, race, face quality), and (iv) probability of true acceptance over time. Our preliminary findings suggest that false rejection rates of one of the COTS matchers remain stable up to approximately 10 years time interval.
Relevant Publication(s)
1. L. Best-Rowden and A. K. Jain, "A Longitudinal Study of Automatic Face Recognition", ICB, Phuket, Thailand, May 19-22, 2015. [pdf]
References
[1] S. Yoon and A. K. Jain, "Longitudinal Study of Fingerprint Recognition", Tech. Report MSU-CSE-14-3, Michigan State University, East Lansing, MI, USA, Jun. 2014.
[2] P. Grother, J. R. Matey, E. Tabassi, G.W. Quinn, and M. Chumakov. IREX VI: Temporal Stability of Iris Recognition Accuracy. NIST Interagency Report 7948, Jul. 2013.
Biomedical Informatics
PHENOTREE: Large-Scale Hierarchical Phenotyping via Sparse Principal Component Analysis
Electronic health records (EHRs) capture comprehensive patient information in digital form from a variety of sources. Increasing availability of the EHRs has facilitated development of data and visual analytics tools, which significantly improved many aspects of healthcare analytics, especially clinical decision support and patient care management systems. The fundamental problems facing many medical data analytics tools include study of patient population, exploring complicated interactions among patients and their medical histories, and extracting phenotypes characterizing the patient population. Another challenge of EHRs is the visualization of the data in a way that clinicians can easily comprehend and interpret different patterns, and trends in patient populations. In this paper, we propose PHENOTREE a novel data-driven, hierarchical, and visually interactive phenotyping method via sparse principal component analysis (SPCA). Specifically, given the EHRs of a patient cohort the proposed framework can identify key features characterizing them using SPCA, and subtype those patients according to the identified key medical features. As such, the population can be iteratively refined (subtyped) according to the key medical features, and phenotypes at various levels of granularity can be formed. We provide an efficient SPCA algorithm and a visualization approach to illustrate the relations between diagnoses which helps to interpret the insights of patient populations in the cohort. The benefits of P HENO T REE are demonstrated through its application in the EHRs of two patient cohorts which are public and private datasets with 101,767 and 223,076 patients, respectively. Our evaluations show that PHENOT REE is beneficial to the detection of clinically meaningful hierarchical phenotypes.
Relevant Publication(s)
I. M. Baytas, K. Lin, F. Wang, A. K. Jain and J. Zhou, "PHENOTREE: Large-Scale Hierarchical Phenotyping via Sparse Principal Component Analysis", IEEE Transactions on Multimedia Special Issue on Visualization and Visual Analytics for Multimedia, 2016 (submitted).[pdf]
Stochastic Convex Sparse Principal Component Analysis
Principal Component Analysis (PCA) is a dimensionality reduction and data analysis tool commonly used in many areas. The main idea of PCA is to represent high dimensional data with a few representative components that capture most of the variance present in the data. However, there is an obvious disadvantage of traditional PCA when it is applied to analyze data where interpretability is important. In applications, where the features have some physical meanings, we lose the ability to interpret the principal components extracted by conventional PCA because each principal component is a linear combination of all the original features. For this reason, sparse PCA has been proposed to improve the interpretability of traditional PCA by introducing sparsity to the loading vectors of principal components. The sparse PCA can be formulated as an 1 regularized optimization problem, which can be solved by proximal gradient methods. However, these methods do not scale well because computation of the exact gradient is generally required at each iteration. Stochastic gradient framework addresses this challenge by computing an expected gradient at each iteration. Nevertheless, stochastic approaches typically have low convergence rates due to the high variance. In this paper, we propose a convex sparse principal component analysis (Cvx-SPCA), which leverages a proximal variance reduced stochastic scheme to achieve a geometric convergence rate. We further show that the convergence analysis can be significantly simplified by using a weak condition which allows a broader class of objectives to be applied. The efficiency and effectiveness of the proposed method are demonstrated on a large scale electronic medical record cohort.
Relevant Publication(s)
I. M. Baytas, K. Lin, F. Wang, A. K. Jain and J. Zhou, "Stochastic Convex Sparse Principal Component Analysis", To appear in EURASIP Journal on Bioinformatics and Systems Biology, 2016.[pdf]
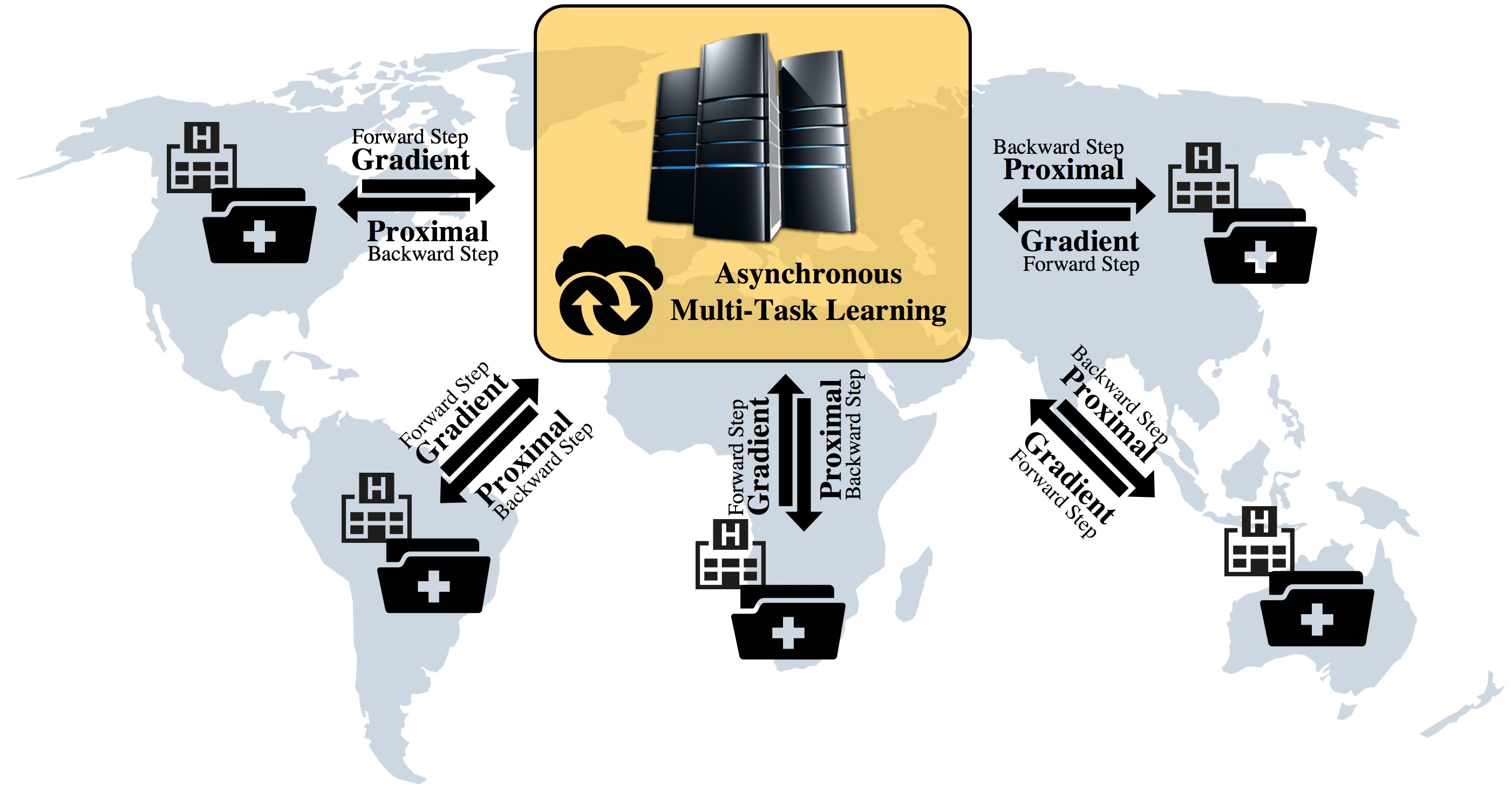
Distributed Asynchronous Multi-Task Learning
Distributed Asynchronous Multi-Task Learning
Real-world machine learning applications involve many learning tasks that are inter-related. For example, in the healthcare domain, we need to learn a predictive model of a certain disease for many hospitals. The models for each hospital can be different because of the inherent differences in the distributions of the patient populations. However, the models are also closely related because of the nature of the learning tasks namely modeling the same disease. By simultaneously learning all the tasks, the multi-task learning (MTL) paradigm performs inductive knowledge transfer among tasks to improve the generalization performance of all tasks involved. When datasets for the learning tasks are stored in different locations, it may not always be feasible to move the data to provide a data-centralized computing environment, due to various practical issues such as high data volume and data privacy. This has posed a huge challenge to existing MTL algorithms. In this paper, we propose a principled MTL framework for distributed and asynchronous optimization. In our framework, the gradient update does not depend on and hence does not require waiting for the gradient information to be collected from all the tasks, making it especially attractive when the communication delay is too high for some task nodes. Empirical studies on both synthetic and real-world datasets demonstrate the efficiency and effectiveness of the proposed framework.
Relevant Publication(s)
I. M. Baytas, M. Yan, A. K. Jain, J. Zhou, "Asynchronous Multi-Task Learning", To appear in IEEE International Conference on Data Mining (ICDM) 2016.[pdf]
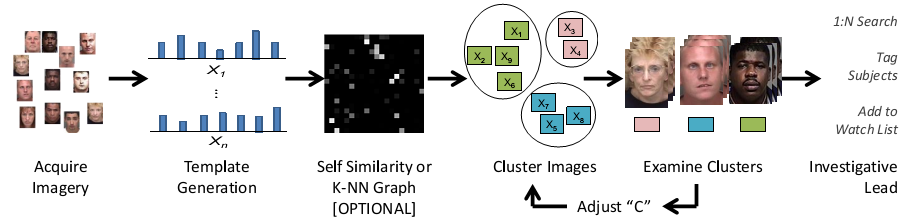
Face Image Clustering
Face Image Clustering
Investigations that require the exploitation of large volumes of face imagery are increasingly common in current forensic scenarios (e.g., Boston Marathon bombing), but effective solutions for triaging such imagery (i.e., low importance, moderate importance, and of critical interest) are not available in the literature. General issues for investigators in these scenarios are a lack of systems that can scale to volumes of images over 100K, and a lack of established methods for clustering the face images into the unknown number of persons of interest contained. As such, we explore best practices for clustering large sets of face images into large numbers of clusters as a method of reducing the volume of data to be investigated by forensic analysts (Fig. 1).
Relevant Publication(s)
1. C. Otto, B. Klare, and A. K. Jain, "An Efficient Approach for Clustering Face Images", ICB, Phuket, Thailand, May 19-22, 2015.[pdf]
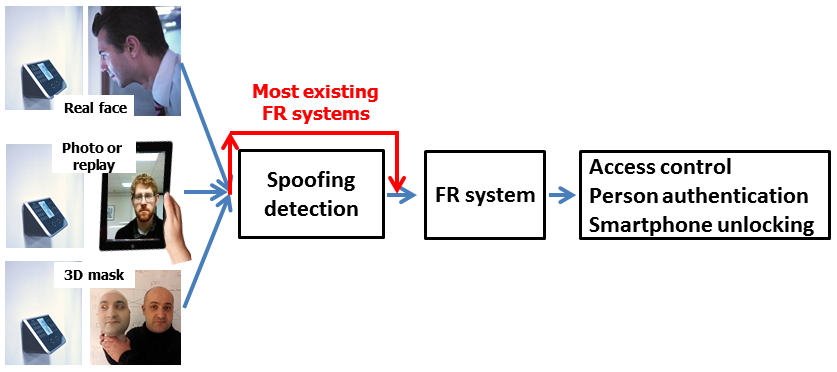
Face Liveness
Face Liveness
The popularity of face recognition has raised concerns about face spoof attacks (also known as biometric sensor presentation attacks), where a photo or video of an authorized person's face could be used to gain access to facilities or services. While a number of face spoof detection techniques have been proposed, their generalization ability has not been adequately addressed. In this project, we propose a new method for face liveness detection based on image quality analysis from 2D face spoof attacks (printed photos, video replays, etc.). Compared with widely used approaches based on face texture and motion analysis, the image quality analysis does not require face detection. Additionally, spoof detection based on image quality analysis should have better generalization ability than methods based on face texture or motion analysis. We also collect a face spoof database, MSU Mobile Face Spoofing Database (MSU MFSD), using two mobile devices (Google Nexus 5 and MacBook Air) with three types of spoof attacks (printed photo, replayed video with iPhone 5S, and iPad Air). The cross-database performance of individual face liveness detection methods is an important topic in this project.
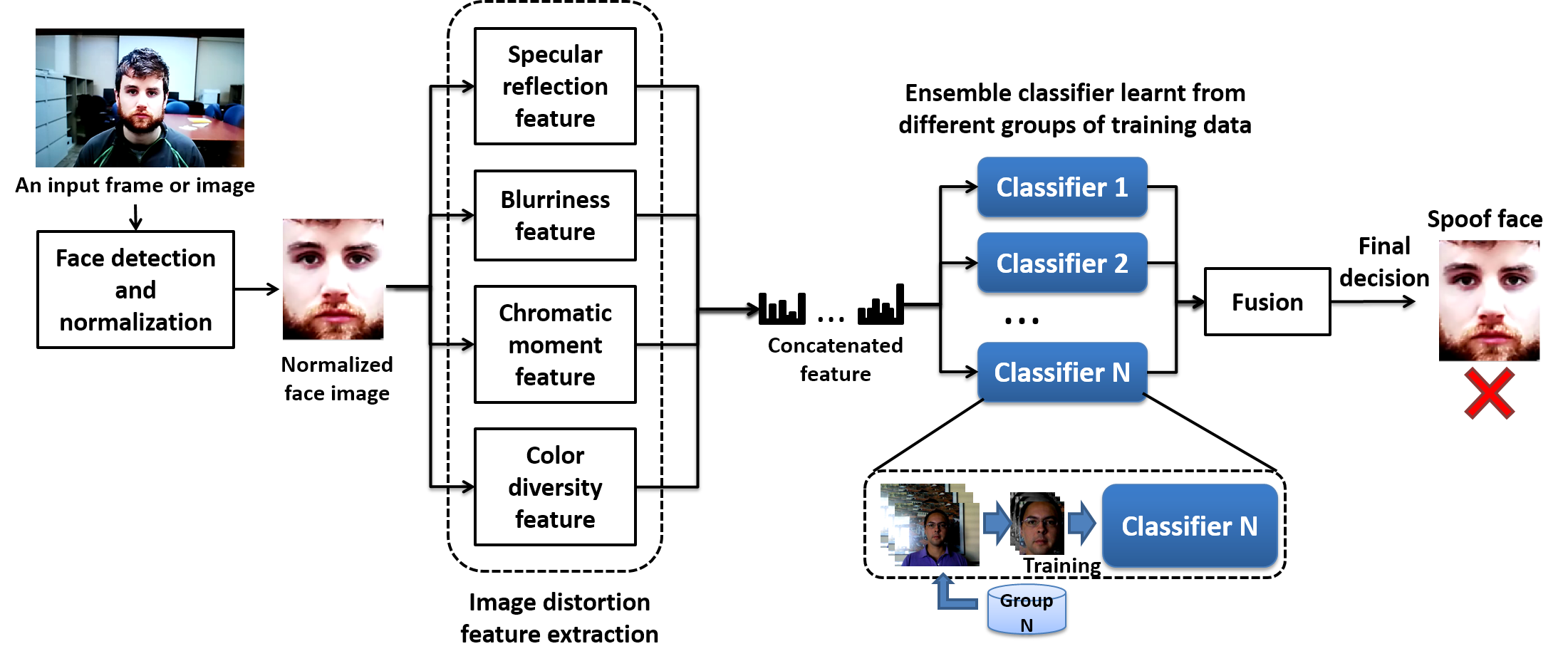
In [1] we used image distortion analysis (IDA) to classify whether an input to a facial recognition system is of a genuine user or a spoof user. Four different features (specular reflection, blurriness, chromatic moment, and color diversity) are extracted to form the IDA feature vector. Experiments show our classifier based on IDA generalizes well, achieving state of the state performance, especially in cross-database testing, which portrays real world scenarios.
In [2] we address the problem of face spoof detection of replay attacks based on the analysis of aliasing in spoof videos. We analyze the moiré pattern aliasing that commonly appears during the recapture of video or photo replays on a screen in different channels (red, green, blue and grayscale) and regions (the whole face, detected face, facial component between the nose and chin). Multi-scale LBP and DSIFT features are used to represent the characteristics of moiré patterns. Experimental results on Idiap replay-attack and CASIA databases, as well as on a database we collected, Replay Attacks for Smartphones (RAFS), shows that the proposed approach is very effective in face spoof detection for both cross-database and intra-database testing scenarios. An Android application based on [2] has been developed and shows potential to be used for real world application.
Relevant Publication(s)
[1] D. Wen, H. Han, and A. K. Jain, "Face Spoof Detection with Image Distortion Analysis", IEEE Transactions on Information Forensics and Security, Vol. 10, No. 4, pp.746-761, April 2015. [pdf] [database].
[2] K. Patel, H. Han, and A. K. Jain, "Live Face Video vs. Spoof Face Video: Use of Moire Patterns to Detect Replay Video Attacks", ICB, Phuket, Thailand, May 19-22, 2015. [pdf]
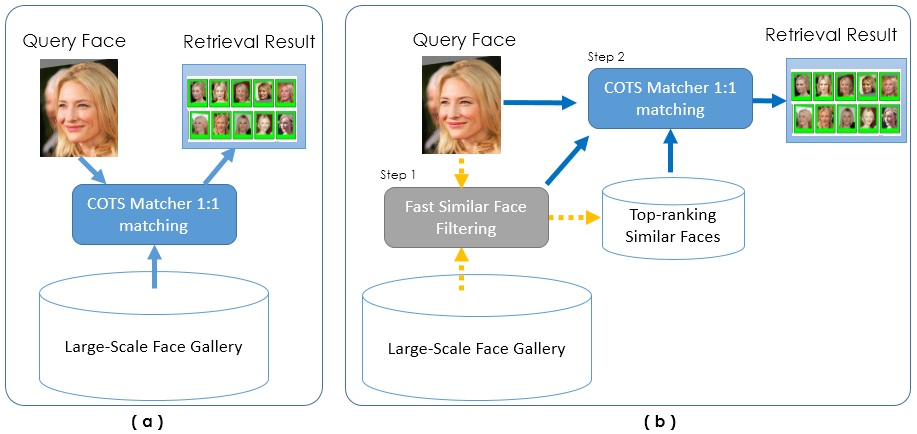
Face Retrieval
Face Retrieval
Face retrieval is an enabling technology for many applications, including automatic face annotation, deduplication, and surveillance. In this project, we aim to build a face retrieval system which combines a k-nearest neighbor search procedure with a commercial-off-the-shelf (COTS) matcher in a cascaded manner (shown in Fig. 1). In particular, given a query face image, we first pre-filter the gallery set and find the top-k most similar faces for the query image by using deep facial features that are learned offline with a deep convolutional neural network. The top-k most similar faces are then re-ranked based on score-level fusion of the similarities between deep features and the COTS matcher.
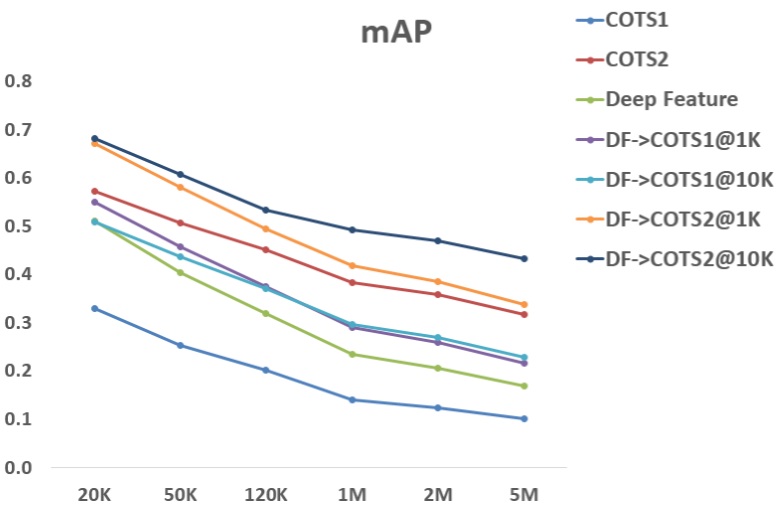
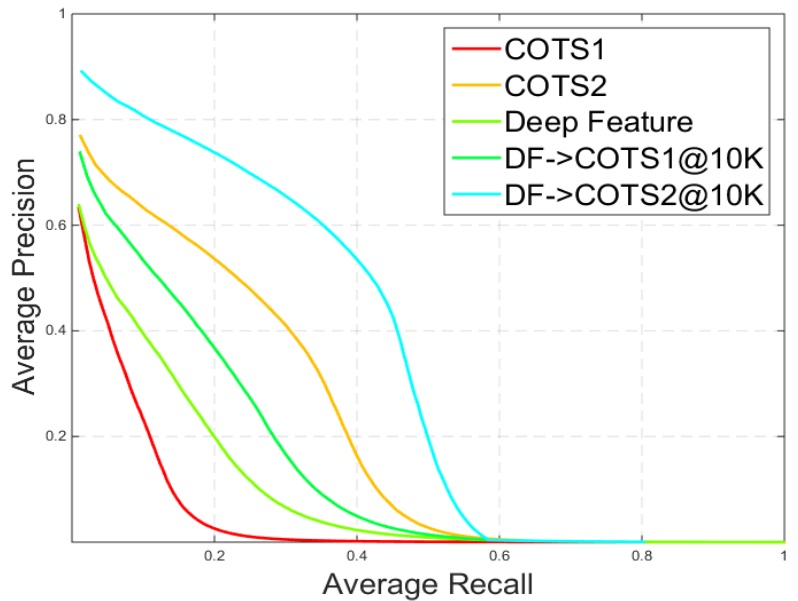
The proposed retrieval system can address performance and scalability simultaneously. The retrieval system is evaluated on a large-scale web face database (5 million images). The gallery set is constructed with four different web face databases (Pubfig, LFW, WLFDB, and WebFace). All overlapping subjects are removed. The proposed system is compared with two commercial face matchers, and achieves the best performance.
| SOURCE | #SUBJECT | #IMAGES | |
|---|---|---|---|
| QUERY SET | Pubfig | 100 | 2,000 |
| GALLERY SET | Pubfig | 100 | 36,061 |
| LFW | 5,446 | 11,173 | |
| WLFDB | 3,000 | 100,575 | |
| WebFaces | 4,881,187 | ||
| TOTAL | 5,000,000 |
| Pubfig[1] | LFW[2] | WLFDB[3] | Web Faces |
|---|---|---|---|
 |
 |
 |
 |
Relevant Publication(s)
1. Dayong Wang and A. K. Jain, "Face Retriever: Pre-filtering the Gallery via Deep Neural Net", ICB, Phuket, Thailand, May 19-22, 2015. [pdf]
References
[1] Neeraj Kumar, Alexander C. Berg, Peter N. Belhumeur, and Shree K. Nayar, "Attribute and Simile Classifiers for Face Verification,", International Conference on Computer Vision (ICCV), 2009.[web page]
[2] Gary B. Huang, Manu Ramesh, Tamara Berg, and Erik Learned-Miller. "Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments", University of Massachusetts, Amherst, Technical Report 07-49, October, 2007. [web page]
[3] Wang, Dayong, Hoi, Steven C. H., He, Ying, Zhu, Jianke, Mei, Tao and Luo, Jiebo, Retrieval-Based Face Annotation by Weak Label Regularized Local Coordinate Coding, IEEE Trans. Pattern Anal. Mach. Intell., Vol. 36, No. 3, p.550–563, mar, 2014.[web page]

Image Capture and Persistence of Fingerprint Recognition for Infants and Toddlers
Image Capture and Persistence of Fingerprint Recognition for Infants and Toddlers
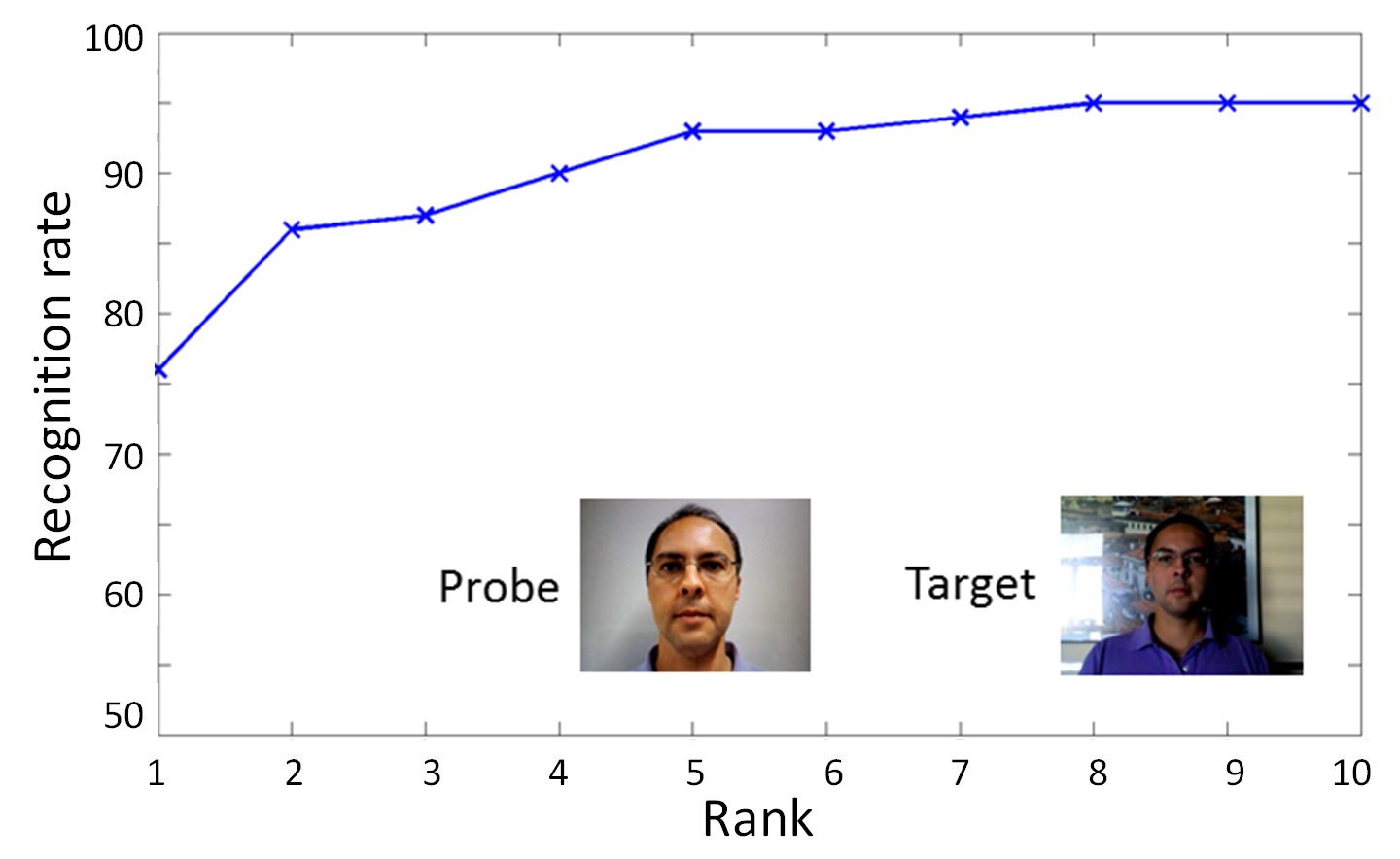
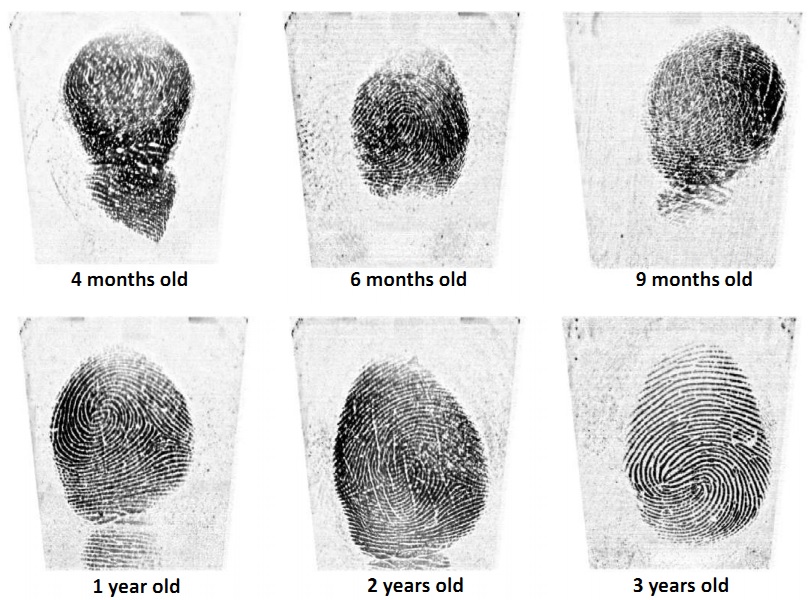
With a number of emerging applications requiring biometric recognition of children (e.g., tracking child vaccination schedules, identifying missing children and preventing newborn baby swaps in hospitals), investigating image capture of biometric traits of children and temporal stability of biometric recognition accuracy for children is important. Image capture and persistence of recognition accuracy of three of the most commonly used biometric traits (fingerprints, face and iris) has been investigated for adults. However, they have not been studied systematically for children in the age group of 0-4 years. Given that very young children are often uncooperative and do not comprehend or follow instructions, in our opinion, among all biometric modalities, fingerprints are the most viable for recognizing children. This is primarily because it is easier to capture fingerprints of young children compared to other biometric traits, e.g., iris, where a child needs to stare directly towards the camera to initiate iris capture. In this research, our goal is to investigate image capture and persistence of fingerprint recognition for children in the age group of 0-4 years. Based on preliminary results obtained for the data collected in the first phase of our study (see Figs. 1 and 2), use of fingerprints for recognition of 0-4 year-old children appears promising.



Relevant Publication(s)
1. A. K. Jain, S. S. Arora, L. Best-Rowden, K. Cao, P. S. Sudhish and A. Bhatnagar, "Biometrics for Child Vaccination and Welfare: Persistence of Fingerprint Recognition for Infants and Toddlers", MSU Technical Report, MSU-CSE-15-7, April 15, 2015. [pdf]
2. A. K. Jain, K. Cao and S. S. Arora, "Recognizing Infants and Toddlers using Fingerprints: Increasing the Vaccination Coverage", IJCB, Clearwater, Florida, USA, Sept. 29-Oct. 2, 2014. [pdf]

Similarity Learning via Adaptive Regression and Its Application to Image Retrieval
Similarity Learning via Adaptive Regression and Its Application to Image Retrieval
We study the problem of similarity learning and its application to image retrieval with large-scale data. The similarity between pairs of images can be measured by the distances between their high dimensional representations, and the problem of learning the appropriate similarity is often addressed by distance metric learning. However, distance metric learning requires the learned metric to be a PSD matrix, which is computational expensive and not necessary for retrieval ranking problem. On the other hand, the bilinear model is shown to be more flexible for large-scale image retrieval task, hence, we adopt it to learn a matrix for estimating pairwise similarities under the regression framework. By adaptively updating the target matrix in regression, we can mimic the hinge loss, which is more appropriate for similarity learning problem. Although the regression problem can have the closed-form solution, the computational cost can be very expensive. The computational challenges come from two aspects: the number of images can be very large and image features have high dimensionality. We address the first challenge by compressing the data by a randomized algorithm with the theoretical guarantee. For the high dimensional issue, we address it by taking low rank assumption and applying alternating method to obtain the partial matrix, which has a global optimal solution. Empirical studies on real world image datasets (i.e., Caltech and ImageNet) demonstrate the effectiveness and efficiency of the proposed method.
Relevant Publication(s)
Q. Qian, I.M. Baytas, R. Jin, A.K. Jain, S. Zhu, “Similarity Learning via Adaptive Regression and Its Application to Image Retrieval”, arXiv:1512.01728 [cs.LG], 2015.[pdf]
Completed Projects
This section contains selected project abstracts and related publications. Please visit our publications page for a comprehensive list of projects, patents, books, and dissertations.
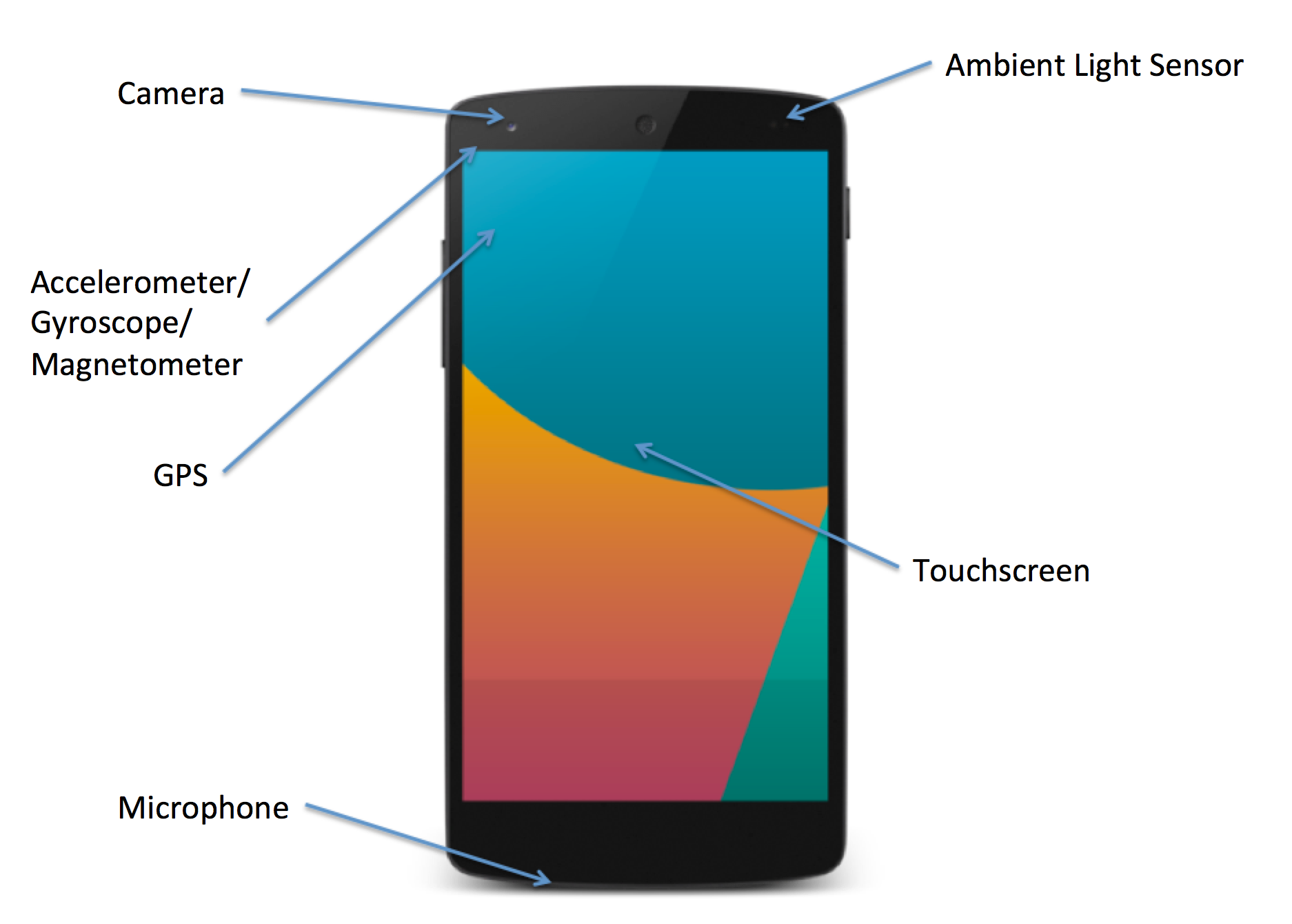
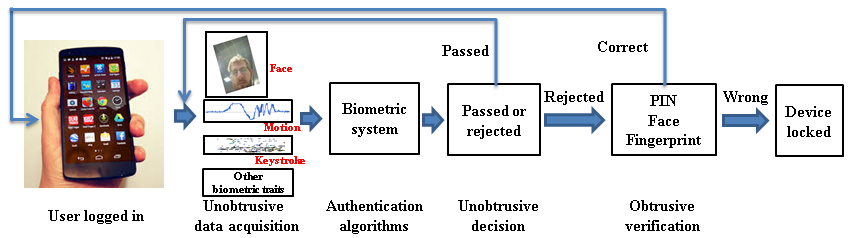
Continuous Authentication of Mobile User
Continuous Authentication of Mobile User
By the end of 2014, there were about 1.7 billion smartphone users worldwide. Mobile devices can carry large amounts of personal data but are often left unsecured. PIN locks are inconvenient to use and thus have seen low adoption (33% of users). While biometrics are beginning to be used for mobile device authentication, they are used only for initial unlock. Mobile devices secured with only login authentication are still vulnerable to theft in an unlocked state. This project studies a face-based continuous authentication system that operates in an unobtrusive manner. We present a methodology for fusing mobile device (unconstrained) face capture with gyroscope, accelerometer, and magnetometer data to correct for camera orientation and, by extension, the orientation of the face image. The project demonstrates (i) improvement of face recognition accuracy from face orientation correction, and (ii) efficacy of the prototype continuous authentication system. Additional face matching algorithms for matching unconstrained face images, and biometric traits such as motion, keystroke, and context will be studied.
Relevant Publication(s)
1. D. Crouse, H. Han, D. Chandra, B. Barbello, and A. K. Jain, "Continuous Authentication of Mobile User: Fusion of Face Image and Inertial Measurement Unit Data", ICB, Phuket, Thailand, May 19-22, 2015. [pdf]
2. K. Niinuma, H. Han, and A. K. Jain, "Automatic Multi-view Face Recognition via 3D Model Based Pose Regularization", BTAS, Washington, D.C., Sept. 29-Oct. 2, 2013. [pdf]
Demographic Attribute Estimation from Face Images
Demographic Attribute Estimation from Face Images
Demographic estimation entails automatic estimation of age, gender and race of a person from his face image, which has many potential applications ranging from forensics to social media.Automatic demographic estimation, particularly age estimation, remains a challenging problem because persons belonging to the same demographic group can be vastly different in their facial appearances due to intrinsic and extrinsic factors. In this work, we present a generic framework (see Fig. 2) for automatic demographic (age, gender and race) estimation. Given a face image, we first extract demographic informative features via a boosting algorithm; we then employ a hierarchical approach consisting of between-group classification and within-group regression. Quality assessment is also developed to identify low-quality face images from which reliable demographic estimates are difficult to obtain. Experimental results on a diverse set of face image databases, FG-NET (1K images), FERET (3K images), MORPH II (75K images), PCSO (100K images), and a subset of LFW (4K images), show that the proposed approach has superior performance compared to the state of the art. We additionally use crowdsourcing to study the ability of human perception to estimate demographics from face images. A side-by-side comparison of the demographic estimates from crowdsourced data and the proposed algorithm provides a number of insights into this challenging problem.

Relevant Publication(s)
1. H. Han, C. Otto, X. Liu, and A. K. Jain. Demographic Estimation from Face Images: Human vs. Machine Performance. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015 (To Appear). [pdf]
2. H. Han, C. Otto, and A. K. Jain. Age Estimation from Face Images: Human vs. Machine Performance. In Proc. 6th IAPR International Conference on Biometrics (ICB), Madrid, Spain, June 4-7, 2013. [pdf]
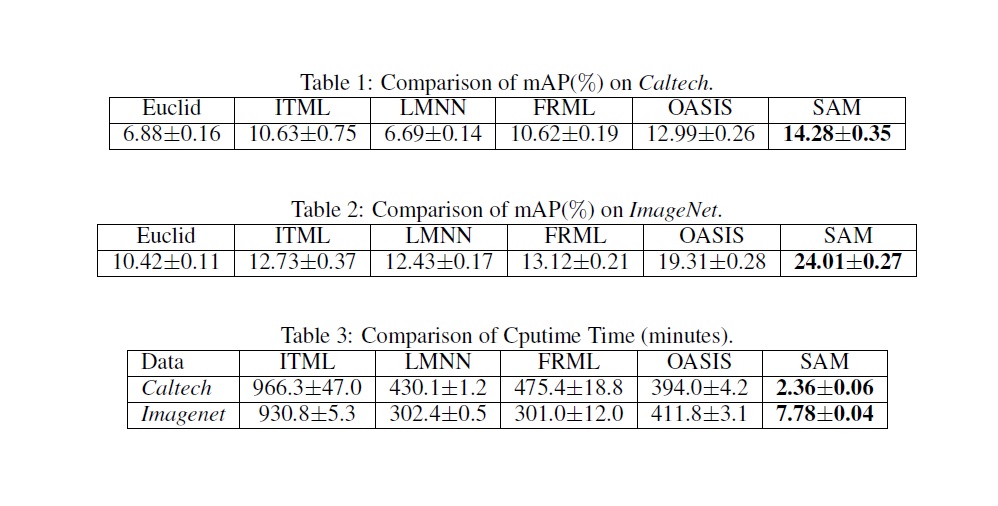
Distance Metric Learning for High Dimensional Data
Distance Metric Learning for High Dimensional Data
A fundamental problem in machine learning is to assess the similarity or dissimilarity between objects, patterns, and data points. Distance metric learning addresses this fundamental issue by learning a distance metric from a set of training examples such that “similar” instances are close to each other while “dissimilar” instances are separated by a large distance. Distance metric learning has been applied to many tasks in computer vision, face detection and recognition, object tracking and video event detection. Nowadays high dimensional data appears in almost every application domain of machine learning. In order to capture diverse pattern in the visual content of images and temporal correlation among video frames, hundreds of thousands of features are extracted, leading to very high dimensional vector representations. Besides high dimensionality, the amount of data available for learning and mining has grown exponentially in recent years. The computational challenge of high dimensional DML arises from the fact that the number of parameters to be estimated increases quadratically in the number of dimensions. The computational challenge is further complicated by the constraint that the learned distance metric has to be a Positive Semi-Definite (PSD) matrix. To ensure a learned distance metric M to be PSD, we need to perform the eigenvalue decomposition of M, an expensive operation whose cost is cubic in the dimensionality. Another concern with high dimensional DML is the overfitting problem. Again, this is because the number of independent variables in distance metric grows quadratically in dimensionality. This project aims to develop efficient learning algorithms to explicitly address the computational challenges in large-scale high dimensional DML. Analysis for better understanding the generalization properties of regularized empirical minimization for high dimensional DML is also developed. In one of the studies conducted in this project, we developed a similarity learning algorithm [1]. We formulated the similarity learning as a matrix regression problem. High dimensionality problem is addressed by taking low rank assumption and solving partial matrix by alternating method. The large scale problem is tried to be solved my utilizing random projections. In the table, comparisons of mean average precisions and computational times for different metric learning methods and the method developed in our study which is denoted as SAM are given.
Relevant Publication(s)
1. Q. Qian, J. Hu, R. Jin, J. Pei and S. Zhu, “Distance Metric Learning Using Dropout: A Structured Regularization Approach”, Proceedings of 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD'14), 2014.

Facial Recognition of Lemurs
Facial Recognition of Lemurs
Lemurs are the world’s most endangered mammals. Analyzing individual lemur movements and interactions among a group of lemurs is essential for tracking the health of lemur populations. Current methods for identifying lemurs are limited to capturing and tagging individuals or visually identifying them via appearance. Tagging individual lemurs is expensive and disruptive to the population both in terms of causing injury and the possibility of group social dynamic shifts. Visual identification requires substantial expertise gained over time and produces results which are difficult to generalize.
Automatic facial recognition of humans is a mature technology and has many uses, from unlocking smartphones to finding suspects in surveillance video. A novel application of this technology, however, is recognizing other mammalian species. By creating a facial detection and recognition application to identify lemurs from images, this project will allow for simple and inexpensive tracking of individual lemurs in their habitat. The presence of distinctive facial features among lemurs allows for accurate recognition by extending and adapting techniques used in human face recognition to the facial anatomy of lemurs.
Relevant Publication(s)
1. Jacobs, RL, Tecot, SR, Klum, S, Crouse, D, Jain, AK (2014) Developing novel face recognition techniques for population assessments and long-term research of threatened lemurs. International Primatological Society XXV Congress, Hanoi, Vietnam.
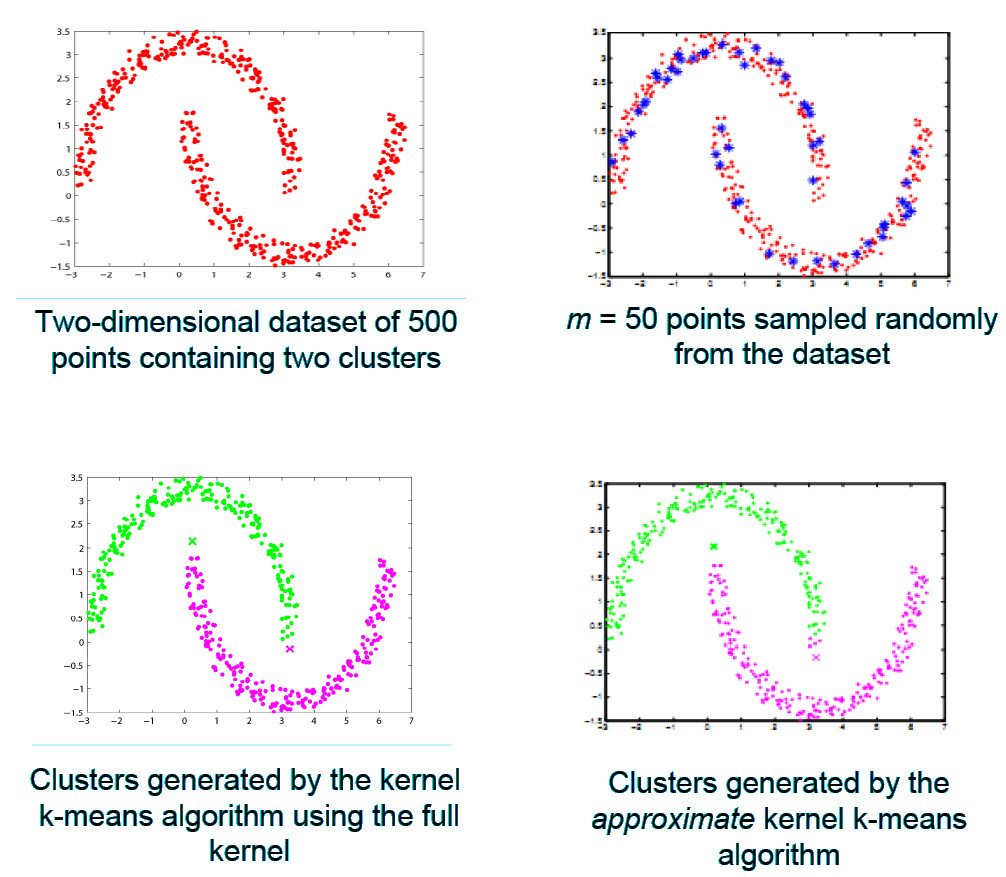
Kernel-Based Clustering for Big Data
Kernel-Based Clustering for Big Data
Kernel-based clustering algorithms achieve better performance on real world data than Euclidean distance-based clustering algorithms. However, kernel-based algorithms pose two important challenges:
- they do not scale sufficiently in terms of run-time and memory complexity, i.e. their complexity is quadratic in the number of data instances, rendering them inefficient for large data sets containing millions of data points, and
- the choice of the kernel function is very critical to the performance of the algorithm.
In this project, we aim at developing efficient schemes to reduce the running time complexity and memory requirements of these clustering algorithms and learn appropriate kernel functions from the data.
Approximate Kernel Clustering
In [1] and [2], we focus on reducing the complexity of the kernel k-means algorithm. The kernel k-means algorithm has quadratic runtime and memory complexity and cannot cluster more than a few thousands of points efficiently. In [1], we developed an algorithm called Approximate Kernel k-means which replaces the kernel similarity matrix in kernel k-means with a low rank approximate matrix, obtained by randomly sampling a small subset of the data set. The approximate kernel matrix is used to obtain the cluster labels for the data in an iterative manner (see Figure 1). The running time complexity of the approximate kernel k-means algorithm is linear in the number of points in the data set, thereby reducing the time for clustering by orders of magnitude (compared to the kernel k-means algorithm). For instance, the approximate kernel k-means algorithm is able to cluster 80 million images from the Tiny data set in about 8 hours on a single core, whereas kernel k-means requires several weeks to cluster them. The clustering accuracy of the approximate kernel k-means algorithm is close to that of the kernel k-means algorithm, and the difference in accuracy reduces linearly with the increase in the number of samples. The approximate kernel k-means algorithm can also be easily parallelized to further reduce the time for clustering. In [2], random projection is employed to project the data in the kernel space to a low-dimensional space, where the clustering can be performed using the k-means algorithm. Figure 2 shows some sample clusters from the Tiny data set obtained using these approximate algorithms.

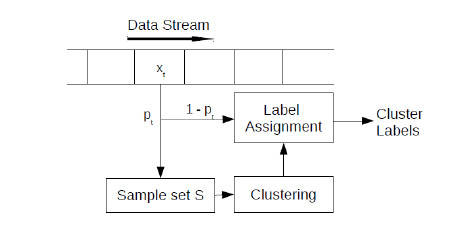
Stream Kernel Clustering
Stream data is generated continuously and is unbounded in size. Stream data clustering, particularly kernel-based clustering, is additionally challenging because it is not possible to store all the data and compute the kernel similarity matrix. In [5], we devise a sampling based algorithm which selects a subset of the stream data to construct an approximate kernel matrix. Each data point is sampled as it arrives, with probability proportional to its importance in the construction of the low-rank kernel matrix. Clustering is performed in linear time using k-means, in a low-dimensional space spanned by the eigenvectors corresponding to the top eigenvalues of the kernel matrix constructed from the sampled points. Points which are not sampled are assigned labels in real-time by selecting the cluster center closest to them (Figure 3). We evaluated this algorithm on the Twitter stream, which was clustered with high accuracy at a speed of about 1 Mbps. Figure 4 shows sample tweets from the cluster representing the #HTML hashtag.
Relevant Publication(s)
[1] R. Chitta, R. Jin, T. C. Havens, and A. K. Jain, "Approximate Kernel k-means: solution to Large Scale Kernel Clustering", KDD, San Diego, CA, August 21-24, 2011.
[2] T. C. Havens, R. Chitta, A. K. Jain, and R. Jin, "Speedup of Fuzzy and Possibilistic Kernel c-Means for Large-Scale Clustering", Proc. IEEE Int. Conf. Fuzzy Systems, Taipei, Taiwan, June 27-30, 2011.
[3] R. Chitta, R. Jin, and A. K. Jain, "Efficient Kernel Clustering using Random Fourier Features", ICDM, Brussels, Belgium, Dec. 10-13, 2012.
[4] R. Chitta, R. Jin, and A. K. Jain, "Scalable Kernel Clustering: Approximate Kernel k-means", arXiv preprint arXiv:1402.3849, 2014.
[5] R. Chitta, R. Jin, and A. K. Jain, "Stream Clustering: Efficient Kernel-Based Approximation using Importance Sampling", (Under Review).
Automated Cancer Detection and Grading
Automated Cancer Detection and Grading
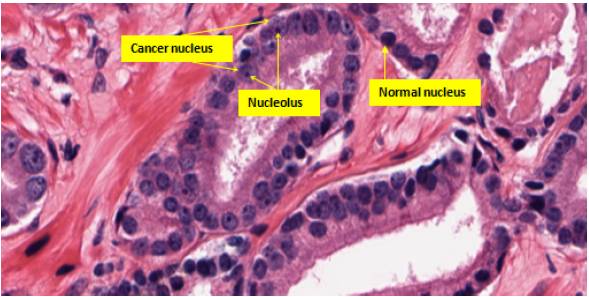
A computer aided system for histological prostate cancer diagnosis can assist pathologists by automating two stages. The first is to locate cancer regions in the large digitized tissue biopsy and the second is to assign grades to those regions. In this project we address both of the stages. In the first stage, besides well-known textural features, we use cytological features which are not utilized in the Gleason grading method to detect cancer regions in a whole slide tissue image at 20x magnification (the size is approximately 5,000x20,000 pixels). One of the most important cytological features is the presence of cancer nuclei (nuclei with prominent nucleoli) in the cancer regions. Both cytological and textural features are extracted from the tissue image and are combined to detect cancer regions.
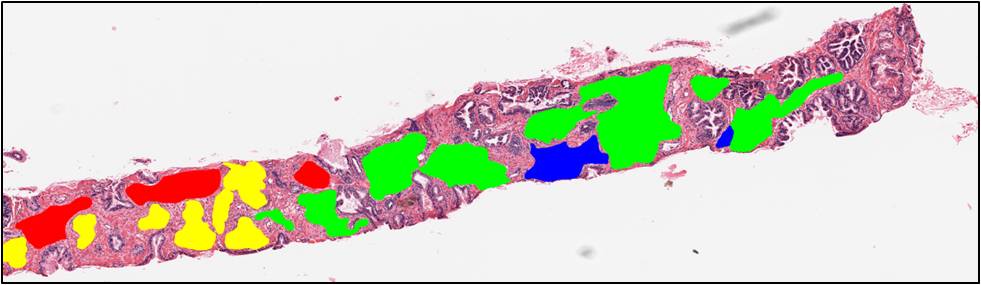
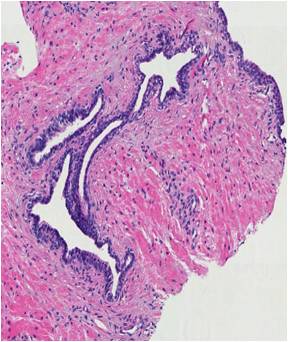
In the second stage, motivated by the Gleason grading method, we aim at classifying a pre-selected region of interest (ROI) into one of the three common categories: benign, grade 3 and grade 4. In the benign ROIs, glands are well-defined with lumina regions in the center, circumscribed by epithelial nuclei and epithelial cytoplasm. In grade 3 ROIs, there appear small, circular glands with thin boundary. Finally, glands start to fuse with each other in grade 4 ROIs. As a result, glands in grade 4 regions do not maintain the well-defined structures as in benign regions. We propose a segmentation-based approach in which we (i) first segment glands from the tissue region, (ii) extract structural features from these segmented glands and (iii) classify the ROI into one of the three classes.
Relevant Publication(s)
K. Nguyen, B. Sabata, and A.K. Jain, "Prostate Cancer Grading: Gland Segmentation and Structural Features", Pattern Recognition Letters, Vol. 33, No. 7, pp. 951-961, May 2012.
K. Nguyen, A. Sarkar, and A. K. Jain, "Structure and Context in Prostatic Gland Segmentation and Classification", In: N. Ayache et al. (eds.) MICCAI 2012, LNCS, Vol. 7510, pp. 115-123, Springer, Heidelberg, 2012.
K. Nguyen, A. K. Jain, and B. Sabata, "Prostate Cancer Detection: Fusion of Cytological and Textural Features", Journal of Pathology Informatics, Vol. 2, No. 2 [p. 3], 2011.
K. Nguyen, A. K. Jain, and B. Sabata, "Prostate Cancer Detection: Fusion of Cytological and Textural Features", MICCAI - Workshop on Histopathology Image Analysis, Toronto, Canada, Sep. 18-22, 2011.
K. Nguyen, A.K. Jain and R. Allen, "Automated Gland Segmentation and Classification for Gleason Grading of Prostate Tissue Images", ICPR, Istanbul Turkey, August 23-26, 2010.
Biometric Template Security

Extended Features in Fingerprints
Extended Features in Fingerprints
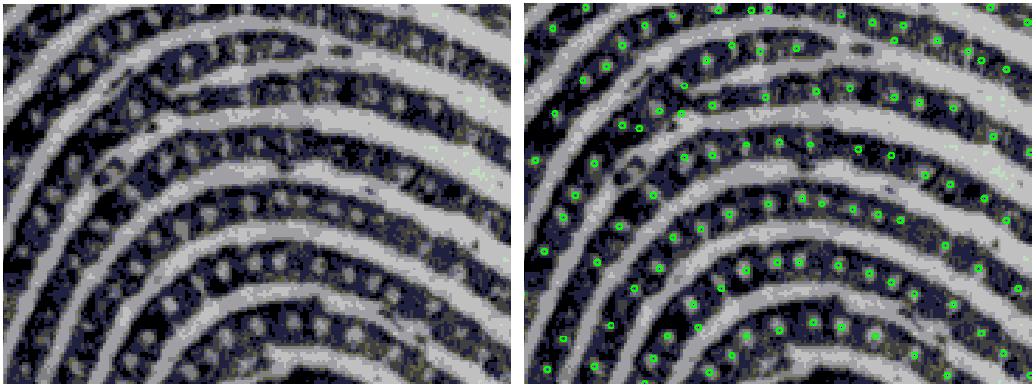
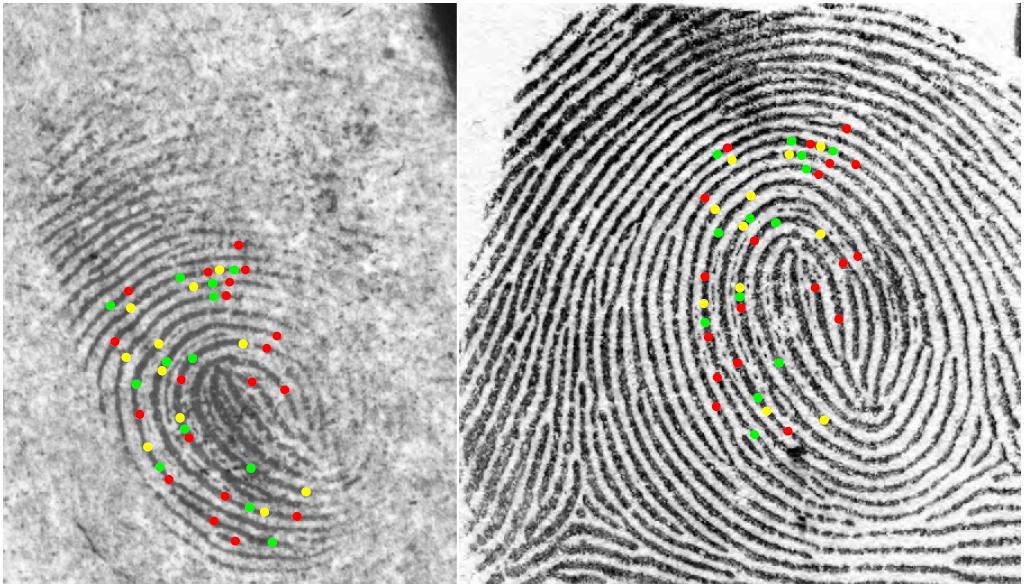
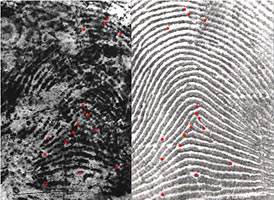
Automatic Fingerprint Identification Systems (AFIS) have for a long time used only minutiae for fingerprint matching. But minutiae are only a small subset of fingerprint details routinely used by latent examiners for fingerprint matching. This has generated a lot of interest in extended feature set (EFS) with the aim of narrowing down the gap between the performance of AFIS and latent examiners. Typical extended features include dots, incipient ridges, pores, and ridge edge features, etc. See Fig. 1. Although some researchers reported the effectiveness of extended features in improving automatic fingerprint recognition accuracy by using their own private fingerprint databases and their own in-house fingerprint matchers, it is still not clear if and how much extended features can benefit AFIS when low quality fingerprint images (such as ink and latent fingerprints) are used and when commercial off-the-shelf (COTS) fingerprint matchers are used as the baseline. The goals of this project are: (i) design automatic extraction and matching algorithms for extended features (particularly, pores, dots, incipient ridges, and ridge edge protrusions), (ii) determine the utility of extended features in matching low quality fingerprints and latent fingerprints, (iii) explore how to incorporate extended features into existing AFIS, and (iv) make recommendations regarding the effectiveness of extended features. Fig. 2 shows the pores extracted by using our extraction algorithm in an example fingerprint image, and Fig. 3 shows the mated pores found by using our matching algorithm in a latent and its exemplar fingerprint. According to our preliminary results (see Fig. 4) of matching 131 partial inked fingerprint images against 4,180 rolled inked fingerprint images (all images are of 1,000 ppi), we observed that i) minutiae matchers usually work very well when there is a sufficient number of minutiae, and ii) the contribution of extended features is more effective for fingerprints which have few minutiae or low minutiae match scores.


Relevant Publication(s)
Q. Zhao, J. Feng, and A. K. Jain, "Latent Fingerprint Matching: Utility of Level 3 Features", MSU Technical Report. MSU-CSE-10-14, Aug. 2010.
Q. Zhao and A. K. Jain, "On the Utility of Extended Fingerprint Features:A Study on Pores", CVPR, Workshop on Biometrics, San Francisco, June 18, 2010.

Project: Face Recognition at a Distance
Project: Face Recognition at a Distance
Face recognition systems typically have a rather short operating distance with standoff (distance between the camera and the subject) limited to 1~2 meters. When these systems are used to capture face images at a larger distance (5 m), the resulting images contain only a small number of pixels on the face region, resulting in a degradation in face recognition performance. To address this problem, we propose dual camera system consisting of PTZ and static cameras to acquire high resolution face images up to a distance of 12 meters. The proposed camera system utilizes the coaxial and concentric configuration between the static and PTZ cameras to achieve distance invariance PTZ camera control. We also use a linear prediction model and camera control scheme to mitigate delays in image processing and mechanical camera motion. The proposed system has a larger standoff in face image acquisition and effectiveness in face recognition test.
Relevant Publication(s)
H. Maeng, S. Liao, D. Kang, S.-W. Lee, and A. K. Jain, "Nighttime Face Recognition at Long Distance: Cross-distance and Cross-spectral Matching", ACCV, Daejeon, Korea, Nov. 5-9, 2012.
H. Maeng, H.-C. Choi, U. Park, S.-W. Lee, and A. K. Jain, "NFRAD: Near-Infrared Face Recognition at a Distance", IJCB, Washington, DC, Oct. 11-13, 2011.
H.-C. Choi, U. Park, and A. K. Jain, "PTZ Camera Assisted Face Acquisition, Tracking & Recognition," Biometrics: Theory, Applications and Systems (BTAS), 2010.

Fingerprint Alteration
Fingerprint Alteration
The widespread deployment of Automated Fingerprint Identification Systems (AFIS) in law enforcement and border control applications has heightened the need for ensuring that these systems are not compromised. While several issues related to fingerprint system security have been investigated, including the use of fake fingerprints for masquerading identity, the problem of fingerprint alteration or obfuscation has received very little attention. Fingerprint obfuscation refers to the deliberate alteration of the fingerprint pattern by an individual for the purpose of masking his identity. Several cases of fingerprint obfuscation have been reported in the press (see Fig. 1). Fingerprint image quality assessment software (e.g. NFIQ) cannot always detect altered fingerprints since the implicit image quality due to alteration may not change significantly. The goals of this research include: (i) analyzing altered fingerprints based on a large altered fingerprint database provided to us by a law enforcement agency, (ii) detecting altered fingerprints automatically at a very low false positive rate (i.e., a natural/unaltered fingerprint is misclassified as altered fingerprint), (iii) restoring altered fingerprints in possible cases, and (iv) matching altered fingerprints to their unaltered mates in the database.

Relevant Publication(s)
S. Yoon, J. Feng, and A. K. Jain, "Altered Fingerprints: Analysis and Detection", IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 34, No. 3, pp. 451-464, March 2012.
S. Yoon, Q. Zhao, and A. K. Jain, "On Matching Altered Fingerprints", ICB, New Delhi, India, March 29-April 1, 2012.
A. K. Jain and S. Yoon, "Automatic Detection of Altered Fingerprints", IEEE Computer, Vol. 45, No. 1, pp. 79-82, January, 2012.
J. Feng, A. K. Jain and A. Ross, "Detecting Altered Fingerprints", ICPR, Istanbul, Turkey, August 23-26, 2010.
Fingerprint, Face, Dental Biometrics, Online Signature
General Biometrics
Heterogeneous Face Recognition
Heterogeneous Face Recognition
![\includegraphics[height=1.5in]{projects/heterogeneous/examples/probe/nir.eps}](projects/heterogeneous/img4.png) | ![\includegraphics[height=1.5in]{projects/heterogeneous/examples/probe/thermalOrig.eps}](projects/heterogeneous/img5.png) | ![\includegraphics[height=1.5in]{projects/heterogeneous/examples/probe/sketch.eps}](projects/heterogeneous/img6.png) | ![\includegraphics[height=1.5in]{projects/heterogeneous/examples/probe/forensic.eps}](projects/heterogeneous/img7.png) |
![\includegraphics[height=1.5in]{projects/heterogeneous/examples/gal/nir.eps}](projects/heterogeneous/img8.png) | ![\includegraphics[height=1.5in]{projects/heterogeneous/examples/gal/thermalOrig.eps}](projects/heterogeneous/img9.png) | ![\includegraphics[height=1.5in]{projects/heterogeneous/examples/gal/sketch.eps}](projects/heterogeneous/img10.png) | ![\includegraphics[height=1.5in]{projects/heterogeneous/examples/gal/forensic.eps}](projects/heterogeneous/img11.png) |
| (a) | (b) | (c) | (d) |
A key asset in identification using face recognition technology is the extensive collection of face databases (photographs). The source of these databases range from ID card images (e.g. driver license and passport), visa applications (e.g. U.S. VISIT), and criminal mug shot photographs. Being populated with visible light photographs, commercial-of-the-shelf (COTS) face recognition systems (FRS) used to search these databases expects incoming visible light probe (query) photographs. However, many military and law enforcement scenarios exist where a probe face image is only available in an alternate sensing modality. Consider the following examples: (i) when acquiring a face image in environments with unfavorable illumination (such as night time) or in covert military and intelligence scenarios, infrared imaging must be used to capture a subjectв ¬ !" s face, and (ii) when no opportunity exists to acquire a face image, a forensic sketch must be drawn from a verbal description provide by a witness to a crime. In each of these scenarios the probe image will be from an alternate modality (infrared or sketch) than the images in the gallery (visible light photograph). This identification task, where the probe and gallery images are from different modalities, is called heterogeneous face recognition (HFR). Since only limited data is available on face images in no-visible spectrum (such as a database of infrared face images), accurate HFR systems are vital to enable identification in many critical situations. A COTS FRS performs poorly in heterogeneous face recognition. As a result, specialized matching systems must be developed to enable identification in these sensitive scenarios. This project aims at developing both generic solutions to multiple heterogeneous face recognition scenarios, as well as tailored solutions to specific HFR scenarios.
Relevant Publication(s)
B. Klare and A.K. Jain, "Heterogeneous Face Recognition using Kernel Prototype Similarities", IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012 (To Appear).
H. Han, B. Klare, K. Bonnen, and A. K. Jain, "Matching Composite Sketches to Face Photos: A Component-Based Approach", IEEE Transactions on Information Forensics and Security, 2012 (To Appear).
Z. Lei, S. Liao, A. K. Jain, and S. Z. Li, "Coupled Discriminant Analysis for Heterogeneous Face Recognition", IEEE Transactions on Information Forensics and Security, Vol. 7, No. 6, pp. 1707-1716, December 2012.
Z. Lei, C. Zhou, D. Yi, A. K. Jain, and S. Z. Li, "An Improved Coupled Spectral Regression for Heterogeneous Face Recognition", ICB, New Delhi, India, March 29-April 1, 2012.
A. K. Jain, and B. Klare, "Matching Forensic Sketches and Mug Shots to Apprehend Criminals", IEEE Computer, Vol.44, No. 5, pp. 94-96, May 2011.
B. Klare, Z. Li, and A. K. Jain, "Matching Forensic Sketches to Mugshot Photos", IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 33, No. 3, pp. 639-646, March, 2011.
B. Klare and A. K. Jain, "Heterogeneous Face Recognition: Matching NIR to Visible Light Images", ICPR, Istanbul, Turkey, August 23-26, 2010.
B. Klare and A. K. Jain, "Sketch to Photo Matching: A Feature-based Approach",Proc of SPIE, Biometric Technology for Human Identification VII, April 2010.

Kernel Methods for Multi-label Learning and Object Categorization
Kernel Methods for Multi-label Learning and Object Categorization
We are interested in the problem of multi-label learning with many classes, where the aim is assigning each instance to related categories (Figure 1). Our goal is to develop kernel methods for multi-label learning. Unlike the conventional approaches that implement multi-label learning as a set of binary classification problems, our goal is to develop direct approaches that would exploit relationships between the class labels, and we proposed multi-label ranking methods for this task (see references below). Moreover, since kernel learning, or more specifically Multiple Kernel Learning (MKL), has attracted considerable amount of interest in computer vision community, we proposed an efficient algorithm for multi-label multiple kernel learning (ML-MKL) – see reference below. We assume that all the classes under consideration share the same combination of kernel functions, and the objective is to find the optimal kernel combination that benefits all the classes.
We also consider a special type of multi-label learning where class assignments of training examples are incomplete. As an example, an instance whose true class assignment is (c1, c2, c3) is only assigned to class c1 when it is used as a training sample. We refer to this problem as multi-label learning with incomplete class assignment (Figure 2). We proposed a ranking based multi-label learning framework (MLR-GL) that explicitly addresses the challenge of learning from incompletely labeled data by exploiting the group lasso technique to combine the ranking errors.

Relevant Publication(s)
S. S. Bucak, R. Jin, and A. K. Jain, "Multi-label Learning with Incomplete Class Assignments," IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2011), Colorado Springs, CO, 2011.
S. S. Bucak, R. Jin, and A.K. Jain, "Multi-label Multiple Kernel Learning by Stochastic Approximation: Application to Visual Object Recognition," NIPS 2010, Vancouver, B.C., Canada, 2010.
S. S. Bucak, P. K. Mallapragada, R. Jin, and A. K. Jain, "Efficient Multi-label Ranking for Multi-class Learning: Application to Object Recognition," International conference on Computer Vision (ICCV 2009), Kyoto, Japan, 2009.
Latent Fingerprint Enhancement
Latent Fingerprint Enhancement
Automatic feature extraction in latent fingerprints is a challenging problem due to poor quality of most latents, such as unclear ridge structures, overlapped lines and letters, and even overlapped fingerprints (see Fig. 1). In the current practice, latent examiners are required to mark minutiae and optionally extended features such as dots, incipient ridges, pore, etc. The goal of this research is to improve the automatic feature extraction accuracy in the enhanced latent fingerprints as well as to provide the enhanced images to the latent examiners for manual markups. In this research project, we are developing a semi-automatic latent fingerprint enhancement algorithm which only requires manually marked region of interest (ROI) and singular points (e.g. core and delta). Marking these features is generally less time-consuming and requires less expertise than marking minutiae. The proposed algorithm consists of two phases: (i) fingerprint orientation field estimation, which fits an orientation field model to the coarse orientation field estimated from skeleton provided by a commercial fingerprint SDK, and (ii) fingerprint ridge enhancement by Gabor filtering. Experimental results on NIST SD27 (a public domain latent fingerprint database) indicate that, by incorporating the proposed enhancement algorithm, the matching accuracy of the commercial matcher was significantly improved. Fig. 2 shows the examples where the proposed enhancement algorithm improves the retrieval rank of the mated fingerprint in the large background database with 15,758 images.


Relevant Publication(s)
J. Feng, J. Zhou, and A. K. Jain, "Orientation Field Estimation for Latent Fingerprint Enhancement", IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012 (To Appear).
S. Yoon, J. Feng, and A. K. Jain, "Latent Fingerprint Enhancement via Robust Orientation Field Estimation", IJCB, Washington, DC, Oct. 11-13, 2011.
S. Yoon, J. Feng, and A. K. Jain, "On Latent Fingerprint Enhancement", Proc. of SPIE, Biometric Technology for Human Identification VII, April 2010.
Latent Fingerprint Matching
Latent Fingerprint Matching
Latent fingerprint identification is of critical importance to law enforcement agencies in identifying suspects. While tremendous progress has been made in plain and rolled fingerprint matching, latent fingerprint matching continues to be a difficult problem. Latent fingerprints are inadvertent impressions left by fingers on surfaces of objects. Poor quality of ridge impressions, small finger area, and large non-linear distortion are the main difficulties in latent fingerprint matching, compared to plain or rolled fingerprint matching. We propose a system for matching latent fingerprints to rolled fingerprints that is needed in forensics applications. In addition to minutiae, we also use extended features, including singularity, ridge quality map, ridge flow map, ridge wavelength map, and skeleton. In order to evaluate the relative importance of each extended feature, these features are incrementally used in the order of their cost in marking by latent experts.
Relevant Publication(s)
A. A. Paulino, J. Feng, and A. K. Jain, "Latent Fingerprint Matching Using Descriptor-Based Hough Transform", IEEE Transactions on Information Forensics and Security, 2012 (To Appear).
A. A. Paulino, J. Feng, and A. K. Jain, "Latent Fingerprint Matching using Descriptor-Based Hough Transform", IJCB, Washington, DC, Oct. 11-13, 2011.
A. K. Jain and J. Feng, "Latent Fingerprint Matching", IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 33, No. 1, pp. 88-100, January, 2011.
A. A. Paulino, A. K. Jain and J. Feng, "Latent Fingerprint Matching: Fusion of Manually Marked and Derived Minutiae", SIBGRAPI, Gramado, Brazil, Aug. 30-Sept. 3, 2010.
J. Feng, S. Yoon, and A. K. Jain, "Latent Fingerprint Matching: Fusion of Rolled and Plain Fingerprints", Proc. International Conference on Biometrics (ICB), June, 2009.
Anil K. Jain, Jianjiang Feng, Abhishek Nagar, and Karthik Nandakumar, “On matching latent fingerprints,” CVPR Workshop on Biometrics, 2008.

Latent Palmprint Matching
Latent Palmprint Matching
The evidential value of palmprints in forensic applications is clear, as about 30% of the latents recovered from crime scenes are from palms. While biometric systems for palmprint-based personal authentication in access control type of applications have been developed, they mostly deal with low resolution (about 100 ppi) palmprints and only perform full-to-full palmprint matching. We propose a latent-to-full palmprint matching system that is needed in forensic applications. Our system deals with palmprints captured at 500 ppi (the current standard in forensic applications) or higher resolution and uses minutiae as features to be compatible with the methodology used by latent experts. Latent palmprint matching is a challenging problem because latent prints lifted at crime scenes are of poor image quality, cover only a small area of the palm, and have a complex background. Other difficulties include a large number of minutiae in full prints (about 10 times as many as fingerprints), and the presence of many creases in latents and full prints. A robust algorithm to reliably estimate the local ridge direction and frequency in palmprints is developed. This facilitates the extraction of ridge and minutiae features even in poor quality palmprints. A fixed-length minutia descriptor, MinutiaCode, is utilized to capture distinctive information around each minutia and an alignment-based minutiae matching algorithm is used to match two palmprints.
Relevant Publication(s)
Anil K. Jain, Jianjiang Feng, “Latent Palmprint Matching”, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 31, No. 6, pp. 1032-1047, 2009.
Matching Sketch to Photos
Matching Sketch to Photos
![\includegraphics[height=1.5in]{images/examples/probe/nir.eps}](projects/sketch_to_photo/GoodSketch1.jpg) | ![\includegraphics[height=1.5in]{images/examples/probe/thermalOrig.eps}](projects/sketch_to_photo/GoodSketch2.jpg) | ![\includegraphics[height=1.5in]{images/examples/probe/sketch.eps}](projects/sketch_to_photo/BadSketch1.jpg) | ![\includegraphics[height=1.5in]{images/examples/probe/forensic.eps}](projects/sketch_to_photo/BadSketch2.jpg) |
![\includegraphics[height=1.5in]{images/examples/gal/nir.eps}](projects/sketch_to_photo/GoodPhoto1.jpg) | ![\includegraphics[height=1.5in]{images/examples/gal/thermalOrig.eps}](projects/sketch_to_photo/GoodPhoto2.jpg) | ![\includegraphics[height=1.5in]{images/examples/gal/sketch.eps}](projects/sketch_to_photo/BadPhoto1.jpg) | ![\includegraphics[height=1.5in]{images/examples/gal/forensic.eps}](projects/sketch_to_photo/BadPhoto2.jpg) |
It is vital for law enforcement agencies to have the capability to identify unknown criminals using any various forms of available information. Forensic sciences often focus on this goal: given a latent fingerprint, DNA sample, or digital image of a suspect, accurately determine their identity. A profound improvement on this identification task has been observed through the development and progression of biometric technologies. Given (i) the large collection face image databases (e.g. mug shot, driver license, passport), and (ii) many opportunities to acquire face images from both the ubiquity of cameras and generation of forensic sketches, increasing the accuracy of face identification technology is of significant benefit to the criminal justice community.
Forensic sketches are drawn by a police artist based on a verbal description of the appearance of a subject provided by a witness or the victim. Commercial-of-the-shelf (COTS) face recognition systems (FRS) are not designed to match forensic sketches to photograph images, which limits the paradigm for utilizing forensic sketches to dissemination of the composite to media outlets and law enforcement agencies with the goal of someone recognizing the individual depicted in the image. Considering the (i) time spent generating a single forensic sketch, (ii) economic impact of disseminating the sketch to media outlets and law enforcement agencies, and (iii) egregious nature of crimes that are typically committed by culprits depicted in the composites (e.g. murder, sexual assault, armed robbery), progress in the ability to automatically match these sketches to the extensive face databases available is paramount. The goal of this research is to develop matching system specially designed to match forensic sketches to photograph databases.
Matching with the FaceSketchID System
Relevant Publication(s)
H. Han, B. Klare, K. Bonnen, and A. K. Jain, "Matching Composite Sketches to Face Photos: A Component-Based Approach", IEEE Transactions on Information Forensics and Security, 2012 (To Appear).
A. K. Jain, and B. Klare, "Matching Forensic Sketches and Mug Shots to Apprehend Criminals", IEEE Computer, Vol.44, No. 5, pp. 94-96, May 2011.
B. Klare, Z. Li, and A. K. Jain, "Matching Forensic Sketches to Mugshot Photos", IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 33, No. 3, pp. 639-646, March, 2011.
B. Klare and A. K. Jain, "Sketch to Photo Matching: A Feature-based Approach",Proc of SPIE, Biometric Technology for Human Identification VII, April 2010.

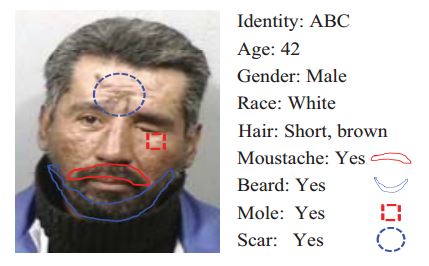
Matching and Retrieving of Face Images Based on Facial Marks
Matching and Retrieving of Face Images Based on Facial Marks
Soft biometric traits embedded in a face (e.g., gender and facial marks) are ancillary information and are not fully distinctive by themselves in face recognition tasks. However, this information can be explicitly combined with face matching score to improve the overall face recognition accuracy. Moreover, in certain application domains, e.g., visual surveillance, where a face image is occluded or is captured in off-frontal pose, soft biometric traits can provide even more valuable information for face matching or retrieval. Facial marks can also be useful to differentiate identical twins whose global facial appearances are very similar. The similarities found from soft biometrics can also be useful as a source of evidence in courts of law because they are more descriptive than the numerical matching scores generated by a traditional face matcher. We propose to utilize demographic information (e.g., gender and ethnicity) and facial marks (e.g., scars, moles, and freckles) for improving face image matching and retrieval performance. An automatic facial mark detection method has been developed that uses 1) the active appearance model for locating primary facial features (e.g., eyes, nose, and mouth), 2) the Laplacian-of-Gaussian blob detection, and 3) morphological operators.
Relevant Publication(s)
B. Klare, A. A. Paulino, and A. K. Jain, "Analysis of Facial Features in Identical Twins", IJCB, Washington, DC, Oct. 11-13, 2011.
U. Park and A. K. Jain, "Face Matching and Retrieval Using Soft Biometrics," IEEE Transactions on Information Forensics and Security, Vol. 5, No. 3, pp. 406-415, 2010.
A. K. Jain and U. Park, "Facial Marks: Soft Biometric For Face Recognition," Proc. of Int. Conf. on Image Processing (ICIP), 2009.

Project: Models for Age Invariant Face Recognition
Project: Models for Age Invariant Face Recognition
Aging variation poses one of the major problems to automatic face recognition systems. Most of the face recognition studies that have addressed the aging problem have focused on age estimation or aging simulation. However, research on age invariant face recognition is limited. Designing an appropriate feature representation and an effective matching framework for age invariant face recognition remains an open problem. In this paper, we propose a discriminative model to address face matching in the presence of age variation. In this framework, we first represent each face using two patch-based local feature representations, one based on scale invariant feature transform (SIFT) and the other based on multi-scale local binary patterns (MLBP). Since both SIFT-based features and MLBP-based features span a high-dimensional feature space, to reduce the feature dimensionality and avoid the over fitting problem, we use multi-feature discriminant analysis (MFDA) to process these two local feature spaces in a unified framework. The MFDA integrates two different random sampling techniques (random subspace and bagging) to improve the performance of linear discriminant analysis (LDA). By random sampling the training set as well as the feature space, several LDA-based classifiers are constructed and then combined to generate a robust decision via a fusion rule. Experimental results show that our approach outperforms a state-of-the-art commercial face recognition engine on MORPH, a large-scale public domain face aging dataset. We also compare the performance of the proposed discriminative model with a generative aging model. A fusion of discriminative and generative models further improves the face identification accuracy in the presence of aging.
Relevant Publication(s)
C. Otto, H. Han, and A. K. Jain, "How Does Aging Affect Facial Components", ECCV WIAF Workshop, Florence, Italy, Oct. 7-13, 2012.
B. Klare and A. K. Jain, "Face Recognition Across Time Lapse: On Learning Feature Subspaces", IJCB, Washington, DC, Oct. 11-13, 2011.
Z. Li, U. Park, and Anil K. Jain, "A Discriminative Model for Age Invariant Face Recognition," IEEE Transactions on Information Forensics and Security, Vol. 6, No. 3, pp. 1028-1037, September 2011.
U. Park, Y. Tong, A. K. Jain, "Age Invariant Face Recognition", IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 32, No. 5, pp. 947-954, May, 2010.
U. Park, Y. Tong, and A. K. Jain, "Face Recognition with Temporal Invariance: A 3D Aging Model," Proc. of Int'l Conf. on Automatic Face and Gesture Recognition, Amsterdam, Netherlands, pp. 1-7, 2008.
Multibiometrics
Multibiometric Traits of Identical Twins
Multibiometric Traits of Identical Twins
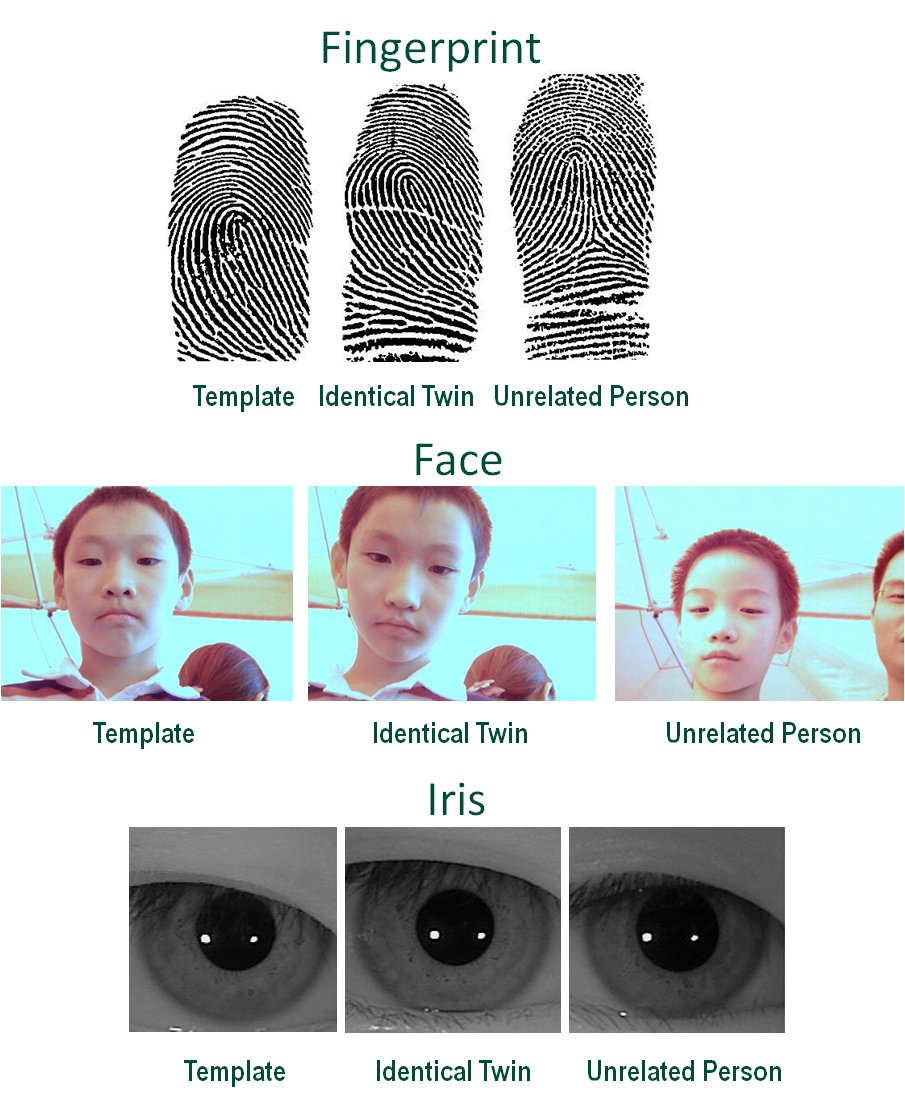
The increase in twin births has created a requirement for biometric systems to accurately determine the identity of a person who has an identical twin. The discriminability of some of the identical twin biometric traits, such as fingerprints, iris and palmprints, is supported by anatomy and the formation process of the biometric characteristic, which state they are different even in identical twins due to a number of random factors during the gestation period. For the first time, we collected multiple biometric traits (fingerprint, face and iris) of 66 families of twins and we performed unimodal and multimodal matching experiments to assess the ability of biometric systems in distinguishing identical twins. Our experiments show that unimodal finger biometric systems can distinguish two different persons who are not identical twins better than they can distinguish identical twins; this difference is much larger in the face biometric system and it is not significant in the iris biometric system. Multimodal biometric systems that combine different units of the same biometric modality (e.g. multiple fingerprints or left and right irises) show the best performance among all the unimodal and multimodal biometric systems, achieving an almost perfect separation between genuine and impostor distributions.
Relevant Publication(s)
Z. Sun, A. A. Paulino, J. Feng, Z. Chai, T. Tan, A. K. Jain, "A Study of Multibiometric Traits of Identical Twins",Proc of SPIE, Biometric Technology for Human Identification VII, April 2010.
Semi-supervised Learning

Tattoo Image Matching and Retrieval
Tattoo Image Matching and Retrieval
Tattoo images on the human body have been routinely collected and used in law enforcement to assist in suspect and victim identification. However, the current practice of matching tattoos is based on keywords. Assigning keywords to individual tattoo images is both tedious and subjective. We have developed a content-based image retrieval system for a tattoo image database. The system automatically extracts image features based on the Scale Invariant Feature Transform (SIFT). Side information, i.e., body location of tattoos and tattoo classes, is utilized to improve the retrieval time and retrieval accuracy. Geometrical constraints are also introduced in SIFT keypoint matching to reduce false retrievals.
Relevant Publication(s)
A. K. Jain, R. Jin, and J.-E. Lee, "Tattoo Image Matching and Retrieval", IEEE Computer, Vol. 45, No. 5, pp. 93-96, May, 2012.
J-E. Lee, W. Tong, R. Jin, and A. K. Jain, "Image Retrieval in Forensics: Tattoo Image Database Application", IEEE Multimedia, Vol. 19, No. 1, pp. 40-49, 2012.
A. K. Jain, J.-E. Lee, R. Jin, N. Gregg, "Content Based Image Retrieval: An Application to Tattoo Images", Proc. International Conference on Image Processing, Nov., 2009.
Data Clustering Projects
For our research on data clustering, visit the data clusteringpage.